Presenting: ZAP
ZAP (Zero-Shot AutoML with Pretrained Models) is a domain-independent meta-learning approach that learns a zero-shot surrogate model for the problem describe above. I.e., at test time, for a new dataset D, ZAP selects the proper DL pipeline, including the pre-trained model and finetuning hyperparameters, using only trivial meta-features, such as image resolution or the number of classes. This process is visualized in the following figure: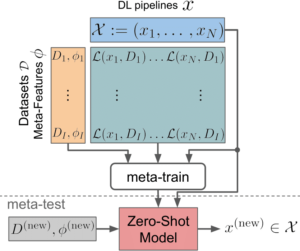
Two stage process of ZAP-HPO
- A framework for choosing a pretrained model and finetuning hyperparameters to finetune a new dataset by meta-learning a domain-independent zero-shot surrogate model using trivial meta-features.
- The release of a large DL image classification meta-dataset that is 1000 times larger than existing ones. This contains the performance of 525 DL pipelines, consisting of the pretrained model, finetuning hyperparameters, and training data metadata across various datasets and augmentations [Github Link].
- Our approach outperforms other contenders in the AutoDL challenge evaluation.
ZAP-AS with AutoFolio
Our first approach for solving ZAP treated the selection of the deep learning (DL) pipeline as an algorithm selection (AS) problem. Algorithm selection is the classic problem due to Rice (dating back to 1976!) of identifying the best algorithm from a pool of candidate algorithms based on dataset meta-features. A strong method from the literature for solving AS is Autofolio, which offers diverse approaches, including regression, classification, clustering, and cost-sensitive classification, to select the best candidate pipeline for a given dataset.ZAP-HPO
Our second approach also accounts for the fact that the different DL pipelines we consider are related to each other. We use this to reframe the DL pipeline selection problem as one of hyperparameter optimization, where the choice of pretrained model is a categorical value and the parameters for finetuning are continuous variables. We use a surrogate function to estimate the test cost of finetuning a pretrained model on a dataset using the choice of pretrained model, finetuning hyperparameters, and dataset meta-features. This is optimized with a pairwise ranking strategy using a ranking loss. The loss function increases the gap between the scores of high and poor-performing pipelines. This is visualized in the following figure: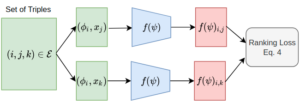
Visual representation of the ranking objective used in testing
Creation of the Candidate DL pipelines (Meta dataset)
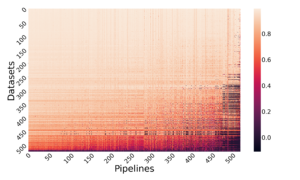
Cost matrix as a heatmap, where color indicates the ALC score and ligher is better.
About the AutoDL Challenge
One way in which we evaluate our ZAP methods is with respect to how well they do in an existing challenge setting. The AutoDL challenges are a series of machine learning competitions focusing on applying Automated Machine Learning (AutoML) to various data modalities, including image, video, text, speech, and tabular data. Due to training time limitations, participants are evaluated using an anytime learning metric and must use efficient techniques. The competition starts with a 20-minute initialization, followed by 20-minutes of training and testing with the test data to provide predictions. The primary evaluation metric is the Area under the Learning Curve (ALC), and the model must generate predictions as early as possible to maximize the ALC since probing is costly.Evaluation and Experiments
We compared the performance of ZAP-AS and ZAP-HPO against previous AutoDL challenge winners, including Baselines (DeepWisdom, DeepBlueAI, PASA-NJU), Random Selection (taken from 525 pipelines), Single-best (best pipeline averaged across the datasets), and the Oracle (best pipeline per dataset). We evaluated two benchmarks, the AutoDL benchmark and our ZAP benchmark based on the ZAP meta dataset. For the AutoDL benchmark, we meta-trained the candidates on the entire meta-dataset and uploaded them to the official platform for evaluation. We reported results from the performance of the five undisclosed final datasets from different domains. For the ZAP Benchmark, we used the Leave-One-Core-Dataset-Out protocol, meta-training the methods on 34 of the 35 datasets, testing on the held-out dataset, and repeating 35 times while averaging the results. We reported the evaluation results on each benchmark averaged over ten repetitions.Results
On the AutoDL benchmark, ZAP-HPO outperformed the winner baselines, single-best, and random baselines. On the other hand, when generalizing to out-of-distribution data, the more conservative ZAP-AS method performed slightly better than ZAP-HPO.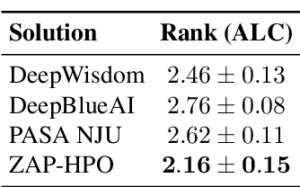
ZAP-HPO approach vs. prior AutoDL winners on the AutoDL benchmark.
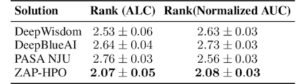
Ranking ZAP-HPO on the ZAP benchmark
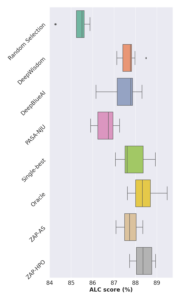
ALC scores of the ZAP approach vs. AutoDL winner baselines
Closing
In conclusion, ZAP expands the scope of AutoML to address the challenge of finetuning pre-trained deep learning models on new image classification datasets. By releasing our metadata dataset, which includes evaluations of 275,000 pipelines assessed on 35 popular image datasets, we have established a foundation for further research in this area, and we hope that other researchers will find it useful. We are working on expanding our framework to include additional models and datasets, and we are also exploring how this approach can extend to other domains. We hope that our work will pave the way for more effective and efficient finetuning of deep learning models, ultimately leading to improved performance across various applications. You can read all the details in our full ICML 2022 paper.Our additional algorithm selection methods:
- Quick-Tune: related to ZAP, Quick-Tune also proposes an efficient method to select an appropriate model and its finetuning hyperparameters but through a meta-learned multi-fidelity performance predictor. In contrast to ZAP, Quick-Tune uses also the training learning curves to arrive at a sophisticated performance predictor. We empirically show that our resulting approach can quickly select a high-performing pretrained model out of a model hub consisting of 24 deep learning models for a new dataset together with its optimal hyperparameters.