2020 is over. Time to look back at the amazing major features we introduced to Auto-Sklearn.
1. Auto-sklearn 2.0
Obviously, the biggest innovation was the release of the next generation of our software: Auto-sklearn 2.0. We already described the details in an earlier blogpost and paper, but here is the short summary:
- Better meta-learning; We now use a pre-computed portfolio with a diverse set of machine learning pipelines that perform best on a wide variety of datasets
- Automated policy selection; Auto-Sklearn now selects the model selection strategy, i.e. holdout vs. cross-validation and whether or not to use Successive Halving, based on experience gained on a large set of experiments
2. More Models & Better Models
Scikit-learn is the most essential component at the core of our package, that’s why we always aim to keep up-to-date with the latest changes. We are happy to say that Auto-sklearn currently features the latest scikit-learn release 0.24.
Additionally, we:
- Added multi-layer networks for classification and regression to our pool of models
- Updated to HistGradientBoosting, a much faster version of Gradient Boosting [PR, video, changelog]
- Reworked existing models to allow iterative fitting to enable Successive Halving
- Enabled multi-output regression
3. Pandas Everywhere: 🐼
Numpy arrays are great, but Pandas dataframes enable directly specifying column types, making it easy to read in mixed featurized data and provide efficient data mingling methods. Thus, Pandas has become an everyday tool for handling data and auto-sklearn now natively supports Pandas arrays as input and treats “categorical” columns as such.
An example of how to use this feature can be found here. Also, check out this example in a binder instance here.
4. Parallelization
Auto-sklearn’s parallelization across multiple cores previously worked by running several SMAC optimization runs in parallel sharing the surrogate model — a method we refer to as pSMAC. Now, we switched to a more principled parallelization strategy implemented via dask. Specifically, now we follow a server – worker architecture and use proper parallel Bayesian optimization. The server schedules configurations from the initial design, from training surrogate model and then maximizing the acquisition function or sampling at random (or when using Successive Halving from promoting configurations from a lower budget)
This has the following advantages:
- More efficient meta-learning. This mostly impacts large datasets where evaluating configurations is expensive. Previously, meta-learning configurations were executed on one core and the other runs already (cold-)started SMAC. Now, all warm-start configurations are executed in parallel and once finished SMAC starts over.
- Better performance. Because information across parallel runs is shared more efficiently.
- Better support for Successive Halving and Hyperband.
5. MyBinder Integration
MyBinder.org is an amazing hosted online service which allows the execution of Jupyter notebooks from within the browser. We have added the necessary scripts so that Auto-sklearn’s examples can be picked up by MyBinder.org. All of Auto-sklearn’s examples can now be executed in the browser without having to install Auto-sklearn or any of its dependencies by clicking ![]() the bottom of an example. Give it a try now by selecting one of the examples from our examples page.
the bottom of an example. Give it a try now by selecting one of the examples from our examples page.
6. Thanks to Our Contributors!
As Auto-sklearn is a community effort, we had a look at who contributed to this package and would like to give a big shout-out to all contributors of 2020:
University of Freiburg:
External:
In numbers we achieved
- merging more than 170 pull requests
- handling 300 issues of which we could close 250
- publishing 9 releases going from version 0.6.0 to version 0.12.1
- having more than 5000 stargazers
An this Figure shows the commit activity per week in 2020: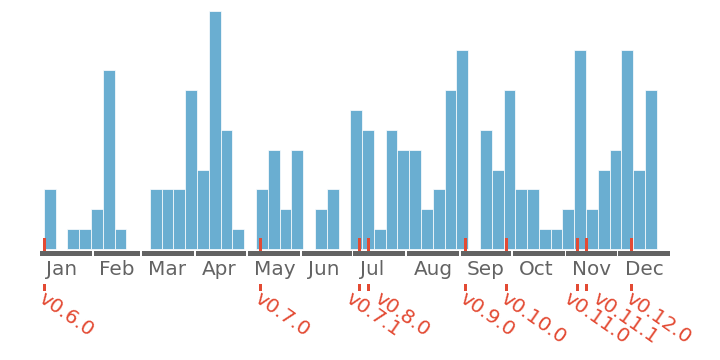
7. Some Last Words
We are always thrilled to hear that Auto-sklearn successfully solved a machine learning problem (and we are also grateful to hear why it didn’t). If you have an interesting application, or are working on getting Auto-sklearn into your pipeline or want to give us feedback, we would love to have a chat to learn how to improve auto-sklearn and make it more applicable to applications. Please don’t hesitate to contact us – drop an email to Matthias or Katharina!
Further information: