In this blog post, we argue why the development of the first generation of AutoML tools ended up being less fruitful than expected and how we envision a new paradigm of automated machine learning (AutoML) that is focused on the needs and workflows of ML practitioners and data scientists.
The Vision of AutoML
The last centuries showed impressively that the democratization of technology led to higher productivity, more wealth, and improved standards of living. As Andrew Ng recently noted in a TED talk, thinking even about the earlier history, the literacy of large parts of the citizens was a crucial step towards advances in science, education, and information sharing. These days, we believe that it is an arguably strong hypothesis that machine learning (ML) has a similar potential to lead to radical changes in many applications. However, we are far away from a democratization of ML, and only a handful of experts with many years of experience can unleash the full potential of this key technology.
Motivated by this observation, the primary vision of AutoML is to enable everyone to use machine learning without deep expertise in ML itself easily. Democratization of ML (a.k.a. AI literacy) was our big dream, and it still is. Of course, AutoML is not the only piece that is required for the democratization of ML, but we deem it to be an extremely important contribution to that goal.
Have we Failed to Reach Out to Our Target Audience?
On the one hand, in line with our vision, we focused on targeting users with little or no ML expertise, e.g., from engineering, biology, chemistry, physics, medicine, and other disciplines. Although the AutoML community achieved tremendous success in improving the capabilities and efficiency of AutoML within the last decade, AutoML is surprisingly still not well established within these disciplines. We blame this on various potential reasons:
- Despite various attempts of our community to make other researchers aware of AutoML, it seems that the amount of people we have reached is still rather limited. With new activities, such as our AutoML fall school, we hope to change that in the future.
- The capabilities of our AutoML tools are not well aligned with their needs. In particular,
- their capabilities are most likely not broad enough by offering only very limited support for data engineering – a task that often requires a significant amount of time and expertise,
- and the black-box nature of most AutoML processes makes it hard to understand why a certain (ensemble of) model(s) is returned at the end of running AutoML.
On the other hand, ML practitioners and data scientists became more and more interested in AutoML techniques and became another primary target audience of AutoML. In fact, it is well known that the configuration of hyperparameters is essential for the successful training of ML models, but at the same time it is a very tedious and error-prone task. Therefore, practitioners have already used the simplest of all AutoML methods for decades, i.e., grid search and random search. Surprisingly, many ML practitioners and users seem to be rather oblivious to the fact that both grid and random search are often fairly inefficient, and modern approaches based on Bayesian optimization, evolutionary strategies, multi-fidelity optimization, or gradient-based optimization can be more efficient by orders of magnitude. Unfortunately, despite the rise of this new target audience, the AutoML community has spent little time thinking about how to adapt their tools for practitioners with ML expertise.
What is holding AutoML back?
By now, there are many hypotheses about what is holding AutoML back from a big success throughout many disciplines and enabling different target groups. To list a few of them:
- AutoML has not yet scaled up to the large state-of-the-art models used in computer vision and NLP.
Remarks: Historically, AutoML was always a step behind the core ML research; in a sense, we started to address the problems of ML researchers and practitioners that were discovered a year or two ago while the core ML researcher set out for the next challenges. Although it is important that the AutoML community plays along this race, we do not believe that this is the most crucial aspect for establishing AutoML on a large user base since not all AI developers aim for these very large models. - While Deep Learning (DL) has Tensorflow and PyTorch, AutoML is missing a base package that is mature enough to be really used in the day-to-day business of practitioners.
Remarks: There is some truth to it since the community has not converged to a single package and the few surviving more than 2-3 years all have their drawbacks. Packages such as Optuna (or also our own SMAC3 package) have gained some traction, but are still behind the quality standards of established DL libraries. - AutoML actually only covers a rather small portion of the data science workflow and thus is only of limited use in practice.
Remarks: Unfortunately, this is indeed true. According to the “State of Data Science” published by Anaconda in 2020, data preprocessing and model selection cover only roughly 11% of the time spent by a data scientist. However, the most time-consuming task, namely data engineering, and in particular data cleansing, is only supported to a very limited degree by our tools, if at all. Although there is some work in this broader field, often referred to as automated data science (AutoDS), corresponding tools are also not sufficiently mature and often tailored to very specific use cases. - AutoML was quite overhyped around 2017-2019, leading to inflated expectations, which could not be fully met in practice.
Remarks: When large tech companies recognized the potential underlying AutoML research, they heavily invested in it both in terms of research grants and staff with the goal to both improve their data science workflows and offer such tools as part of their cloud services. While this led to a significant leap in various aspects of AutoML, it also came with a broad marketing campaign to power sales of corresponding services. Unfortunately, as is often the case with marketing campaigns, the advertised outcomes were best-case scenarios, which could not always be realized in practice, leading to disappointment and underachieved expectations. - There is the belief that many AutoML approaches are not robust, hard to run/implement, and inefficient in parallelizing to leverage large compute resources.
Remarks: That is actually a common argument from people still using random search or even manual tuning. Nevertheless, we strongly recommend trying out modern AutoML packages. Many of them are very easy to run these days, and parallelization is a key feature that is often natively supported. - Both the internal process of AutoML tools and how their final result was constructed is often hard to understand, even for AutoML experts, let alone data scientists, leading to a lack of trust in AutoML systems.
Remarks: It is true that it is hard to understand what AutoML tools are actually doing and why certain design decisions were taken and hyperparameters were chosen. This led to missing trust in AutoML systems, and thus practitioners preferred manual HPO or a simple grid/random search over modern and more complex AutoML tools, because they could easily understand the process and how the result was chosen.
In view of the big success of unexplainable DL models and training processes, the last point regarding understandability and trust is actually a rather surprising hypothesis for the missing success of AutoML. However, if we think more deeply about the common workflow of ML practitioners and data scientists, it becomes clear that AutoML is designed to replace large parts of their day-to-day jobs and less for actually supporting them. So, why should they use AutoML without trusting it and the possibility of explaining design decisions the tools made, but they have to justify for in the end?
So, let us assume that a group of data scientists is willing to use AutoML. They start by feeding their data into the AutoML package, press the magic button, and then have to wait; wait a few minutes, hours, or even days depending on the task, dataset, model, AutoML space, and a plethora of other factors. They have to spend this time without any intermediate feedback or possibilities to observe possibly wrong or suboptimal decisions made by the tool negatively influencing the search process, let alone options to intervene in such cases. As a consequence, it might very well happen that after several days, the AutoML tools return a solution that is unsatisfying for whatever reason.
Coming back to our comparison to DL, the aforementioned process is also unreasonable in that case: Feeding in data to the deep neural network (DNN) and waiting for days before checking its progress. Instead, practitioners start the training process of a DNN and monitor different runs on-the-fly (e.g, by using something like tensorboard or wandb). In case of potential problems, they change the training process or even terminate the training. Thus, although DL is a hard-to-understand process and can require considerable time, researchers and practitioners developed an interactive workflow with rapid prototyping in which they can actively participate.
So our hypothesis is: Instead of replacing the efforts of developers, these developers seek interactive ways for working hand in hand with AutoML tools by making use of the best of both worlds.
The Need for a New Paradigm: Human-Centered AutoML
To put it in exaggerated terms: As a community, we failed to understand the real problems of practitioners before starting to work on solutions. Correspondingly, we believe that it is time for a new paradigm completely rethinking AutoML approaches with the practitioner in mind. We envision it to be:
- A human-centered instead of a machine-centered approach – tailored to the needs and established workflows of practitioners, thus supporting them in their day-to-day business in the most efficient and effective way.
- An understandable AutoML process that shares its insights with the developers to enable them to draw their own conclusions and learn from them.
- Enable practitioners to inject their expertise into the optimization to direct the search in the right direction directly from the start, but also continuously throughout the entire development process.
- Allowing them to inspect and intervene in the process whenever it is required and thus bridging the gap between the traditional interactive data science and the original press-the-button-and-wait AutoML perspective.
The Foundations of this New Paradigm
To understand how we envision this new paradigm to be implemented, let us first think again about the workflow of data scientists. They are often driven by rapid prototyping, i.e., evaluating simple models on parts of the data first, exploring possibilities, gaining insights about the data, required preprocessing, and model classes, followed by continuous re-evaluation. In some sense, that is already what AutoML tools based on the concept of multi-fidelity optimization are doing these days, but without the human in the loop.
However, human expertise can be helpful or even required, for example,
- if the performance metric might be inappropriate and favors actually unwanted models, e.g., with too large inference time or unfair predictions;
- if further metrics are needed to assess the ML pipelines;
- if other pipeline components are needed that are not yet part of the configuration space;
- if further side constraints need to be addressed;
- if the data quality is insufficient and this was not detected prior to applying AutoML leading to poorly performing models;
- if good standard baselines such as random forests perform unexpectedly bad, hinting at some special properties of the modeled learning problem or the data;
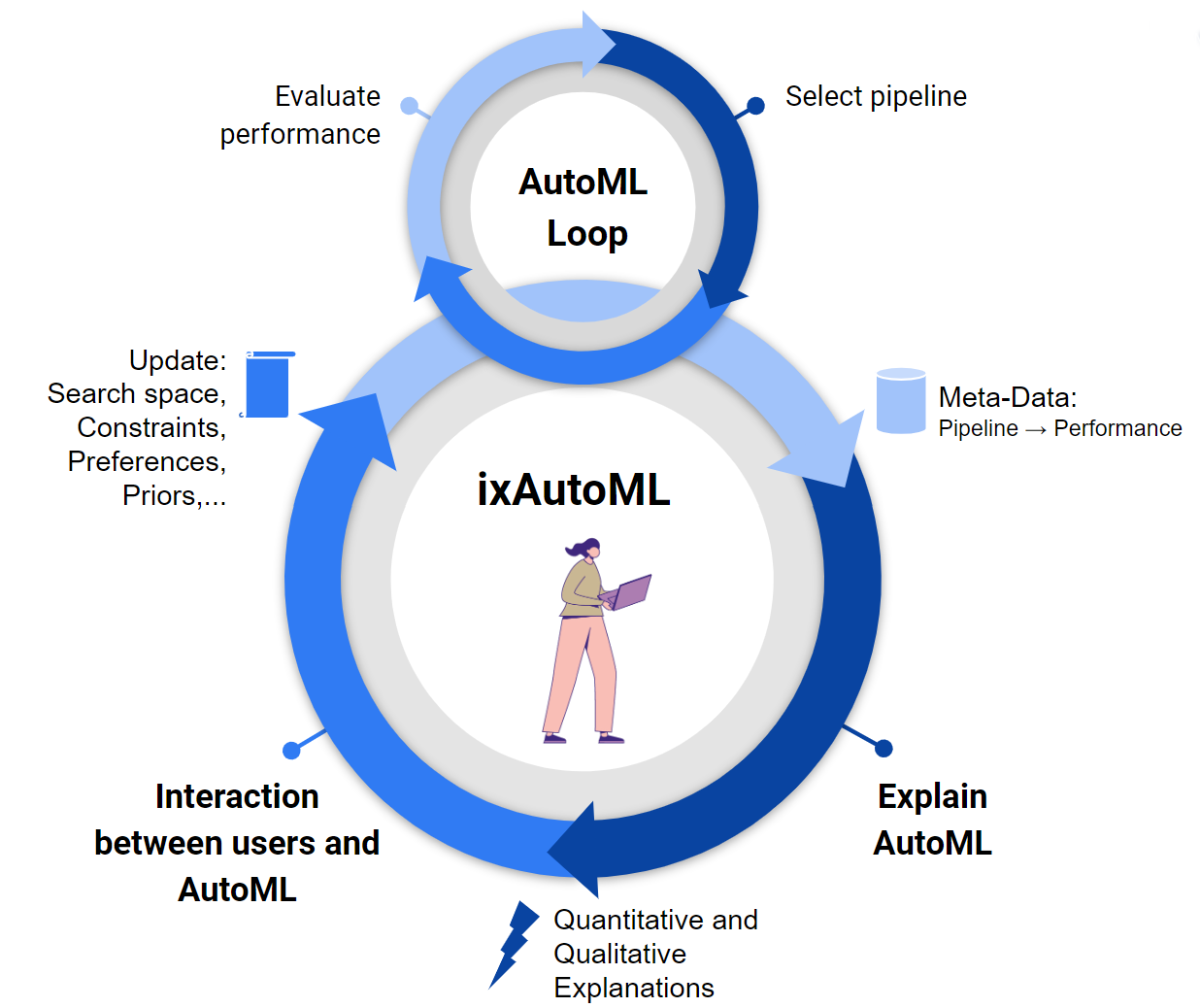
With these considerations in mind, how can we incorporate practitioners back into the loop, such that the overall development of new ML applications is as efficient as possible? We believe that this change requires two components:
- we need methods that help us to gain insights from the AutoML process, i.e., explain AutoML,
- and, based on these insights, we need possibilities to interact with corresponding tools on-the-fly.
Explaining AutoML
Although our group has intensively worked in various collaborations on ideas aimed at making AutoML more explainable, we still have a long way to go. Currently, the few methods going in the direction of explainability in the context of AutoML are mostly centered around hyperparameter importance or hyperparameter effects. Unfortunately, a direct transfer of explainability methods from classical ML is often not possible as the data collected during the AutoML process does not satisfy standard assumptions, in particular, the data points are not independently sampled. Instead, a new pipeline is evaluated and its corresponding performance is collected based on the previously evaluated pipelines and their performances. As such, our data is biased towards well-performing regions of the configuration space, and likewise, other regions are undersampled by the purpose of having efficient optimizers. As we have recently shown [Moosbauer et al. NeurIPS’21], this bias in the data can lead to significantly biased explanations of the interaction between the composition of a pipeline and its performance.
Overall, the main challenge will be to bridge AutoML and interpretable machine learning (iML), extending the latter s.t. corresponding iML methods are applicable to AutoML approaches, and figuring out what is actually needed from the users.
Interacting with AutoML
First AutoML approaches were designed with the idea in mind that users only provide data and maybe specify the configuration space of possible ML pipelines, DL architectures, and hyperparameters. Recent advances also take multiple objectives, constraints, and preferences into account. For example, we recently showed how to make efficient use of expert knowledge about promising configurations [Souza et al. ECML’21, Hvarfner et al. ICLR’22, Mallik et al. MetaLearn’22]. However, these are limited to initial expert beliefs. How would we efficiently do this in an interactive interplay between AutoML and developers? How does this interact with changing preferences, constraints, configuration spaces and more?
Current AutoML approaches for stationary optimization problems have to be changed to non-stationary problems where it is unknown how users can interfere in the process at any moment.
The Vision of Interactive and Explainable AutoML: ixAutoML
We strongly believe that interactive and explainable AutoML (ixAutoML) has the potential to be a game changer in several aspects. It enables:
- Increasing the efficiency of AutoML by making use of the best of both worlds: a systematic search of efficient AutoML approaches and human expertise and intuition;
- A human-in-the-loop AutoML framework that is tailored to the needs of data scientists and thus leading to a more wide spread use of it;
- Insights into the design of ML applications and thus accelerating research on ML by reproducible and insightful tools;
- A platform for teaching people how to use ML effectively based on a hands-on-first principle;
- Eventually, contributing to the democratization of ML;
Marius Lindauer and Alexander Tornede acknowledge funding by the European Union under the ERC Starting Grant ixAutoML (grant no. 101041029). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the ERC. Neither the European Union nor the ERC can be held responsible for them.