By
Compared to the state of computer vision 20 years ago, deep learning has enabled more generic methodologies that can be applied to various tasks by automatically extracting meaningful features from the data. However, in practice those methodologies are not as generic as it looks at first glance. While standard neural networks may lead to reasonable solutions, results can be improved significantly by tweaking the details of this design: both the detailed architecture and several further hyperparameters which control the generalization properties of these networks to unseen data. Efficient AutoML in general and neural architecture search (NAS) in particular promise to relieve us from the manual tweaking effort by tuning hyperparameters / architectures to extract those features that maximize the generalization of neural networks. Motivated by the successes of AutoML and NAS for standard image recognition benchmarks, in our ICCV 2019 paper AutoDispNet: Improving Disparity Estimation with AutoML we set out to also apply them to encoder-decoder vision architectures.
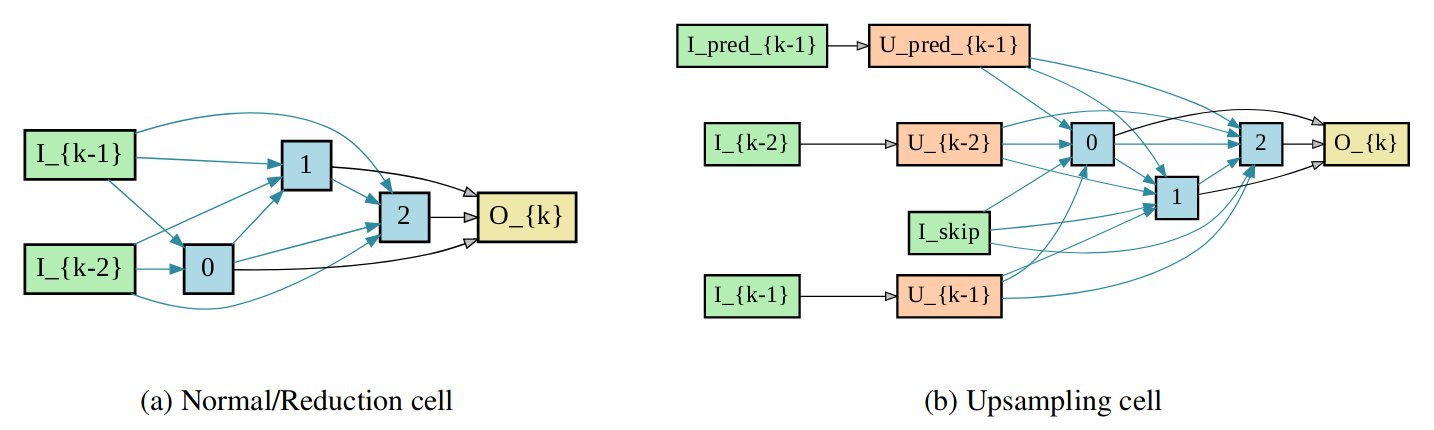 Figure 1: Structure of search cells. (a) structure of a normal or reduction cell. (b) An upsampling cell. In both cases, input nodes are green, intermediate nodes are blue, output nodes are yellow. Upsampling nodes are marked as orange. A blue edge represents transformations done using mixed operations.
Figure 1: Structure of search cells. (a) structure of a normal or reduction cell. (b) An upsampling cell. In both cases, input nodes are green, intermediate nodes are blue, output nodes are yellow. Upsampling nodes are marked as orange. A blue edge represents transformations done using mixed operations.
To address this problem, our lab and the Computer Vision group of the University of Freiburg joined forces to build an automatically learned encoder-decoder architecture for disparity estimation. We adopted DARTS (Differentiable ARchiTecture Search) to search over our space of encoder-decoder architectures. DARTS’ main idea is to have a large supernetwork (also called one-shot model) that includes all architectural choices and to search for an optimal network as a sub-network of this supernetwork. The discrete nature of this optimization problem can be relaxed to a continuous optimization problem, which, together with the regular network training, leads to a bi-level optimization problem. Thanks to its gradient based optimization, DARTS is very efficient and can find an architecture with competitive performance on image classification benchmarks in less than 1 GPU day. However, DARTS only allows the optimization of the architecture but not the training hyperparameters. For the latter, we make use of a multi-fidelity black-box optimization method named BOHB (Bayesian Optimizatioa HyperBand), which combines the best of both worlds, Bayesian Optimization for efficient and model-based sampling and Hyperband for strong anytime performance, scalability and flexibility.
Dense prediction tasks involve mapping a feature representation in the encoder to predictions of larger spatial resolution using a decoder. Therefore, to apply DARTS for disparity estimation we need to extend the architecture search space to support not only normal / reduction convolutional cells, but also upsampling cells (see Figure 1 above). This extension of the search space should be expressive enough to encompass common deep learning best-practices and at the same time have enough flexibility to learn new upsampling transformations.
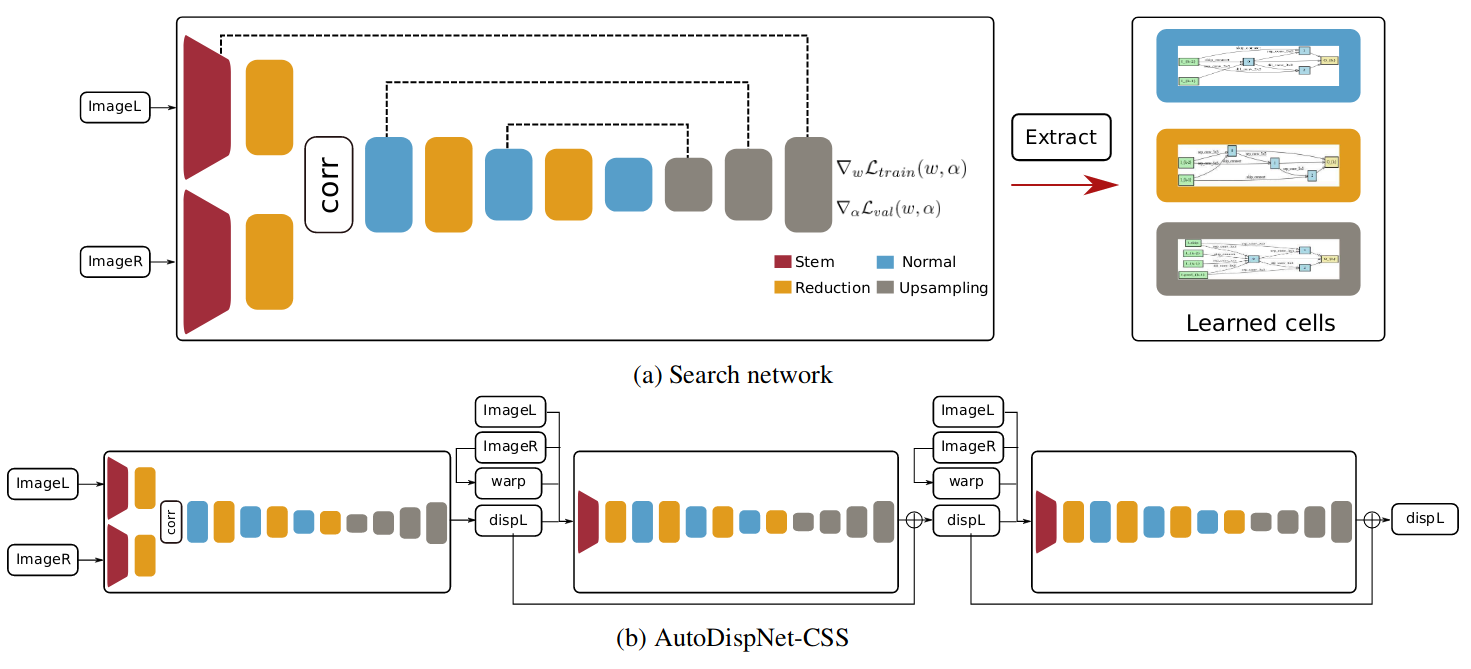 Figure 2: Dense-DARTS for disparity estimation. (a) The search network used to learn cells for disparity estimation. Three types of cells are learned: normal, reduction and upsampling. The stem cells are simple convolutional layers with a fixed structure. It also contains a correlation layer like a standard DispNet-C. Skip connections from encoder to decoder are denoted by the dashed lines. (b) After training, the three cell structures are extracted.Using the extracted cells, a final network (Figure b) is assembled using the CSS structure.
Figure 2: Dense-DARTS for disparity estimation. (a) The search network used to learn cells for disparity estimation. Three types of cells are learned: normal, reduction and upsampling. The stem cells are simple convolutional layers with a fixed structure. It also contains a correlation layer like a standard DispNet-C. Skip connections from encoder to decoder are denoted by the dashed lines. (b) After training, the three cell structures are extracted.Using the extracted cells, a final network (Figure b) is assembled using the CSS structure.
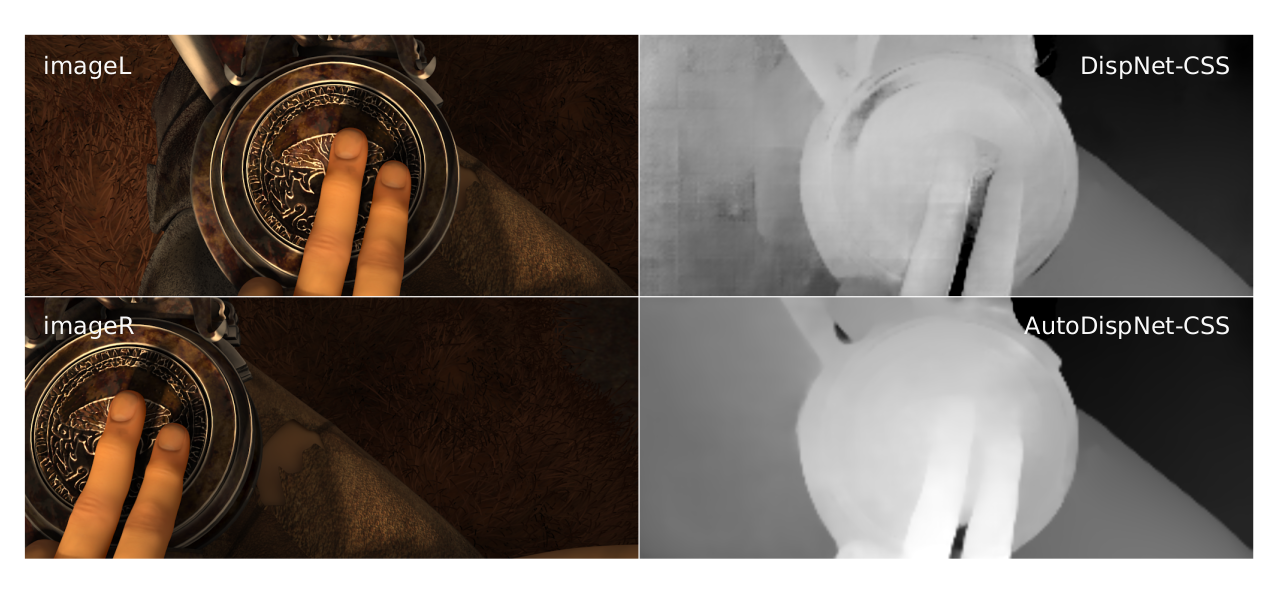
In order to accelerate the optimization process we conduct the DARTS search to find optimal cells in a predefined “macro” DispNet-C-like network. After the architecture search we further tune the hyperparameters, such as the learning rate, weight decay, etc., of the found AutoDispNet-C network using BOHB. The results in the paper and from the plot below show that AutoDispNet-C outperforms the DispNet-C baseline with comparable or less number of parameters and FLOPs. In order to increase the representation strength of our network, we plug the found normal, reduction and upsampling cells found using DispNet-C into the DispNet-CSS structure (introduced in https://arxiv.org/pdf/1808.01838.pdf), which we dub AutoDispNet-CSS, as shown in the figure above. Our experiments demonstrate that AutoDispNet-CSS can achieve state-of-the-art on the Sintel dataset and competitive performance with state-of-the-art manually designed architectures on the public KITTI benchmark.
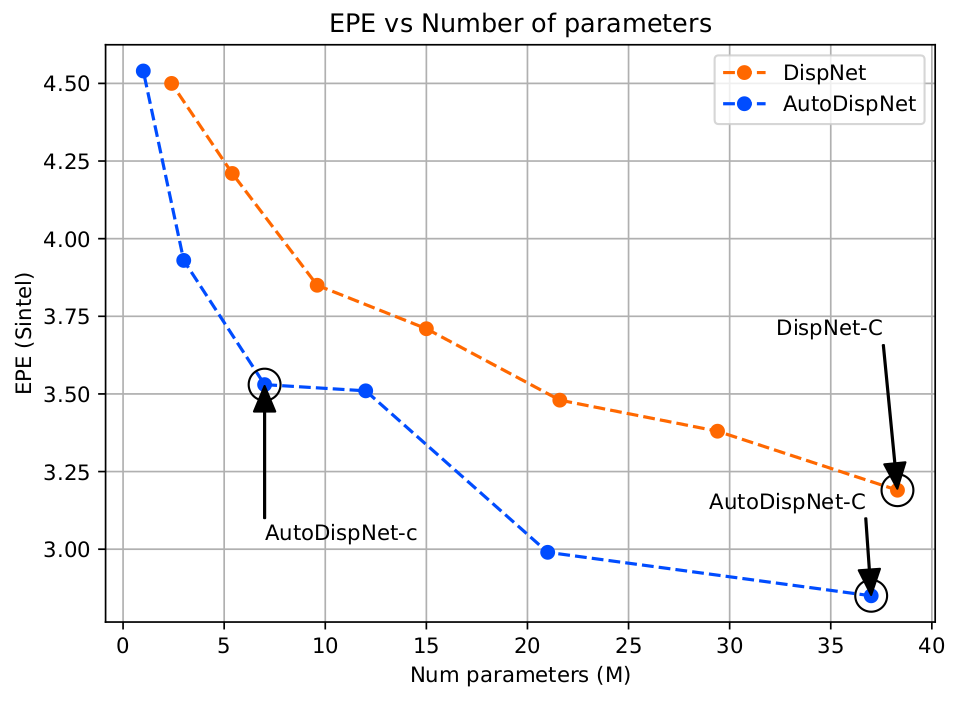 Figure 3: We compare the test performance of smaller DispNet and AutoDispNet architectures. AutoDispNet architectures have a lower error with reduced number of parameters compared to the baseline. The EPE is shown for the Sintel dataset.
Figure 3: We compare the test performance of smaller DispNet and AutoDispNet architectures. AutoDispNet architectures have a lower error with reduced number of parameters compared to the baseline. The EPE is shown for the Sintel dataset.
AutoDispNet provides a new interesting application of neural architecture search and hyperparmeter optimization outperforming human-designed architectures. Interestingly enough, the found architectures do not only outperform the manually designed ones, but the number of parameters and FLOPs required to achieve this performance is also 1.5x smaller. This is partly achieved by a carefully designed search space and the optimization pipeline used, indicating the importance of AutoML in general towards complemeting the skills of human domain experts. Interested in more details? Check out the paper. Also see our other recent NAS papers.