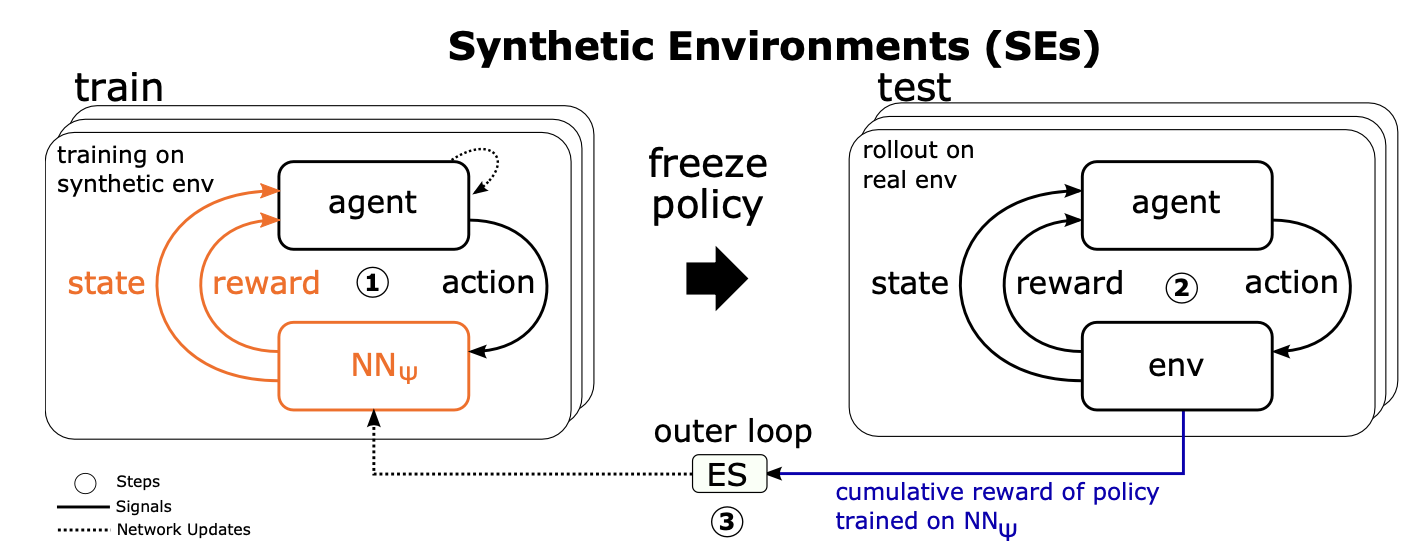
Algorithm benchmarks shine a beacon for machine learning research. They allow us, as a community, to track progress over time, identify challenging issues, to raise the bar and learn how to do better. The OpenML.org platform already serves thousands of datasets together with tasks (combination of a dataset with the target attribute, a performance metric […]
Call for Datasets: OpenML 2023 Benchmark Suites
Posted on April 18, 2023 by Jan van Rijn